Definition Nukleinsäuren
Nukleinsäuren sind sehr große Molekülstrukturen, die aus einzelnen Bausteinen bestehen, nämlich aus Monomeren.
In den Nukleinsäuren werden die Monomere Nukleotide genannt. Diese Nukleotide, bilden verkettet ein Polymer. Dabei kann ein solches Polymer aus Milliarden von Nukleotiden bestehen.
Tatsächlich sind die Nukleinsäuren, genauer gesagt die DNA, die größten zusammenhängenden Molekülstrukturen, die in der Natur bekannt sind.
Nukleinsäuren sind Polymere, die aus Nukleotiden bestehen. Die Nukleinsäuren haben den Zweck, genetische Information zu speichern, diese über Generationen zu übermitteln und die Information in den Lebensvorgängen des Organismus zu nutzen. Es gibt zwei Arten von Nukleinsäuren:
- Die DNA (engl. deoxyribonucleic acid, im dt. DNS, Desoxyribonukleinsäure) und
- die RNA (engl. ribonucleic acid, im dt. RNS, Ribonukleinsäure).
Aufbau DNA und RNA
Die Bezeichnungen der beiden Nukleinsäuren sind fast identisch, und das nicht ohne Grund. Dennoch sind die kleinen Unterschiede im Aufbau der DNA und RNA von entscheidender Bedeutung. Doch zunächst werden die Gemeinsamkeiten der Nukleinsäuren behandelt:
Gemeinsamkeiten DNA und RNA: Aufbau
Die Gemeinsamkeit lässt sich auf den Grundbaustein zurückführen: das Nukleotid. Doch was ist das?
Grundbaustein der Nukleinsäuren: das Nukleotid
Ein Nukleotid bezeichnet einen Baustein der Nukleinsäuren. Dabei setzt es sich aus drei Bestandteilen zusammen:
- Einer Base,
- einem Zucker und
- Phosphat.
Achtung! Ein Nukleosid setzt sich nur aus einer Base und einem Zucker zusammen. Es trägt keine Phosphatgruppen!
Die Base
In der DNA und RNA finden sich fünf verschiedene, stickstoffhaltige Basen: Adenin (A), Guanin (G), Cytosin (C), Thymin (T) und Uracil (U).
Diese lassen sich weiter aufgrund ihrer molekularen Struktur in die Gruppe der Pyrimidine und Purine unterscheiden.
Der Unterschied ist, dass Purine ein Doppelringsystem besitzen, wohingegen Pyrimidine lediglich einen Ring bilden.
Die Namensgebung der Purine hängt mit dem lateinischen Begriff purus zusammen, was so viel wie “rein” bedeutet. Werden Purine vom Menschen aufgenommen, so werden diese zu Harnsäure abgebaut und über die Niere ausgeschieden. Diese Harnsäure wurde erstmals im Jahre 1898 von Emil Fischer synthetisiert. Das Grundgerüst wurde hieraufhin als “Purin” bezeichnet, da es das “reine” Grundgerüst der Harnsäure ist.
Der Zucker
Beide Nukleinsäuren tragen als Zucker eine Pentose, also einen Zucker, der fünf Kohlenstoffatome besitzt.
Das Phosphat
Ein Nukleotid trägt mindestens eine Phosphatgruppe, kann aber gesamt bis zu drei Phosphatgruppen binden.
Je nachdem, wie viele Phosphatgruppen ein Nukleotid trägt, wird es auch unterschiedlich benannt:
- Eine Phosphatgruppe = Nukleosidmonophosphat
- Zwei Phosphatgruppen = Nukleosiddiphosphat
- Drei Phosphatgruppen = Nukleosidtriphosphat
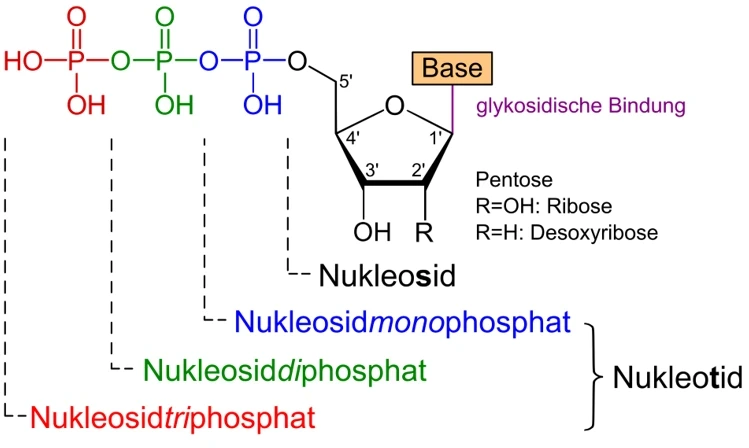
Abbildung 3: Benennung des Nukleosids nach der Anzahl der Phosphatgruppen
Ein Nukleotid in der DNA und RNA trägt immer nur eine Phosphatgruppe.
Nukleotide kommen aber nicht nur in den Nukleinsäuren vor. Vielleicht hast Du bereits von Adenosintriphosphat gehört, oder auch besser bekannt als ATP. Dieses Molekül trägt nämlich drei Phosphatgruppen und wird als “universale Währung” für Energie im Körper verwendet.
Komplementäre Basenpaarung
Sowohl die DNA als auch die RNA haben gemeinsam, dass sie eine komplementäre Basenpaarung zwischen bestimmten Basen eingehen können.
Adenin paart mit Thymin (A–T) und Cytosin mit Guanin (C–G).
So verhält es sich ebenfalls in der RNA, wobei anstelle von Thymin Uracil verwendet wird: (A–U) und (C–G).
Wasserstoffbrückenbindungen besitzen nur einen Bruchteil der Stärke von kovalenten Bindungen, wie sie z. B. zwischen Kohlenstoff (C) und Wasserstoff (H) in Methan auftreten. Allerdings können eine Vielzahl von H-Brücken die Struktur, bspw. die Doppel-Helix-Struktur der DNA, stabilisieren und dabei trotzdem leicht aufgebrochen werden.
Dies ist für biologische Systeme von großer Bedeutung, da die DNA als Informationsträger häufig aufgebrochen werden muss, um sie bspw. zu replizieren oder abzulesen.
Unterschied DNA und RNA – Aufbau
Unterschiede in Ein- und Doppelsträngigkeit
Auch wenn sowohl DNA als auch RNA doppelsträngig vorliegen können, so ist dies überwiegend nur bei der DNA der Fall.
Dabei verlaufen beide Stränge der DNA antiparallel, d. h. in entgegengesetzte Richtungen.
Die RNA hingegen liegt meistens einsträngig vor.
Die Enden der DNA und RNA: 3' oder 5'?
Die Benennung der Enden der DNA und RNA orientiert sich anhand der Nummerierungen der Kohlenstoff-Atome in dem fünfgliedrigen Zucker, der Pentose.
Das Phosphat ist am 5. Kohlenstoff gebunden, weswegen das “Phosphat-Ende” als 5' (sprich: “5 Strich”) benannt wird. Der Zucker ist wiederum an eine Phosphat-Gruppe eines anderen Nukleotids gebunden, und zwar am 3. Kohlenstoffatom der Pentose, weswegen es 3' (sprich: “3 Strich”) genannt wird.
Laufrichtung der DNA und RNA
Aber warum verläuft die “Richtung” der DNA und RNA unterschiedlich?
Die “Richtung” der DNA wird als 3' → 5' angegeben, da in diese Richtung die DNA kontinuierlich von Polymerasen abgelesen wird.
Bei der RNA hingegen wird die Richtung als 5' → 3' bestimmt. Dies hängt damit zusammen, dass die RNA in diese Richtung synthetisiert wird. Wenn nun die DNA in 3' → 5' abgelesen und damit als Matrize – also als Vorlage – verwendet wird, wird die RNA komplementär in Richtung 5' → 3' aufgebaut.
Wenn die RNA nicht doppelsträngig ist, warum sieht tRNA dann so aus?
Vielleicht ist Dir bereits eine Darstellung der Transfer-RNA (kurz: tRNA) begegnet. Sind hierbei nicht klar Doppelstränge zu sehen?
Tatsächlich nicht. Ein Doppelstrang besteht aus zwei Strängen, die tRNA – sowie eine Vielzahl von anderen RNA-Varianten – bestehen aus nur einem Strang, der allerdings mit sich selbst komplementäre Basenpaarungen eingeht.
Unterschiede in Länge der Kette
Ebenso unterscheiden sich die Nukleinsäuren in der Länge der Ketten. Die DNA ist üblicherweise um ein enormes Vielfaches länger als RNA-Moleküle.
DNA-Moleküle sind üblicherweise viele Millionen Basenpaaren lang.
Der Mensch bspw. besitzt sein längstes DNA-Molekül als Chromosom Eins. Dieses umfasst ungefähr 249 Millionen Basenpaare!
RNA-Moleküle reichen von einigen Dutzend Basenpaaren (wie bspw. die RNA-Primer) bis zu einigen Tausend Basenpaaren (wie bspw. die ribosomale RNA, kurz rRNA).
Unterschiede in Verwendung der Pentose
Die DNA verwendet die sogenannte Desoxyribose, wohingegen RNA die Ribose verwendet. Desoxyribose besitzt an dem zweiten Kohlenstoffatom anstelle einer Hydroxygruppe (-OH) lediglich ein Wasserstoffatom (-H).
Welche Bedeutung hat dieser Unterschied?
Die DNA erhält durch die Nutzung von Desoxyribose anstelle von Ribose eine höhere Resistenz gegenüber ungewollter Hydrolyse. Bei dieser wird ein Teil des Zuckers durch eine Reaktion mit Wasser (daher “Hydro”) gespalten.
Das erklärt vermutlich auch, warum die DNA der RNA als Speichermedium der Erbinformation in Lebewesen bevorzugt wird.
Ebenso erhöht sich ihre Flexibilität, weswegen sie sich auch in einer äußerst gewundenen Form, der Doppelhelix, aufstellen kann. Dadurch können enorme Längen der DNA-Moleküle kondensiert werden, d. h. sehr verdichtet werden, um Raum zu sparen.
Das wohl längste Genom – also längsten addierten DNA-Abschnitte in einer Zelle – der Wirbeltiere besitzt der Äthiopische Lungenfisch (wissenschaftlicher Name: Protopterus aethiopicus).

Abbildung 10: Äthiopischer Lungenfisch
Sein Genom umfasst eine atemberaubende Zahl von knapp 133 Milliarden Basenpaaren!
Manche Pflanzen besitzen sogar noch größere Genome, wie bspw. die japanische Lavendelheide (wissenschaftlicher Name: Paris japonica) mit knapp 150 Milliarden Basenpaaren.
Unterschiede in Verwendung der organischen Basen
Anders als die DNA verwendet die RNA anstelle der organischen Base Thymin die Base Uracil.
Diese gehört ebenso zu den Pyrimidinen.
Mehr zu der Base Uracil kannst Du in dem gleichnamigen Artikel “Uracil” erfahren.
Gemeinsamkeiten & Unterschiede DNA und RNA – Funktion
Die Nukleinsäuren DNA und RNA besitzen eine Vielzahl von Funktionen und Besonderheiten.
Gemeinsamkeiten DNA und RNA – Funktion
Die Gemeinsamkeit der DNA und RNA besteht in der Speicherung und Übertragung von Informationen.
Die DNA wird ausschließlich zur Speicherung verwendet. Die Information der DNA in der Zelle kann auf zwei Weisen verwendet werden:
- Replikation: Die Zelle kann die DNA anhand einer Matrize – einer Vorlage, was ein Einzelstrang des Doppelstrangs ist – duplizieren. Dies ist für die kontinuierliche Zellteilung im Körper von großer Bedeutung.
- Transkription: Dies beschreibt den Prozess der Übertragung der Information aus der DNA in ein Überträgermolekül.
Dieses Überträgermolekül ist eine RNA. Wenn diese RNA zur weiteren Synthese von Polypeptiden, also Proteinen, verwendet wird, nennt man dieses Molekül Messenger RNA (kurz: mRNA).
Die Information der DNA wird allerdings nicht nur in eine mRNA übertragen, sondern in eine Vielzahl von RNA-Molekülen, die andere essenzielle Funktionen in der Zelle erfüllen.
Zentrales Dogma der Molekularbiologie
Die Hypothese “Zentrales Dogma der Molekularbiologie” wurde im Jahre 1958 von Francis Crick – ein Entdecker der DNA-Struktur – formuliert.
In dieser beschreibt er, dass die Informationen stets von DNA zur RNA und von der RNA zum Polypeptid fließen. Heute kennt man folgende Richtungen des Informationsflusses:
- DNA → DNA (Replikation),
- DNA → RNA (Transkription),
- RNA → Polypeptid (Translation),
- RNA → RNA (RNA-Replikation),
- RNA → DNA (Reverse-Transkription) und
- DNA → Polypeptid (direkte Translation).
Die ersten drei Wege (Replikation, Transkription, Translation) sind die allgemeinen Übertragungsarten.
Die letzten drei Wege (RNA-Replikation, Reverse-Transkription und direkte Translation) sind spezielle Formen.
Formen der Informationsübertragung, die nach dem Dogma nicht vorgesehen sind, beinhalten immer das Polypeptid als Start:
- Polypeptid → DNA,
- Polypeptid → RNA und
- Polypeptid → Polypeptid.
Genau das ist die Essenz des “Zentralen Dogmas der Molekularbiologie”: Sequenzielle Information, gespeichert in Form eines Polypeptids, kann nicht erneut in DNA oder RNA eindeutig übertragen werden
Zum Begriff Dogma: Ein Dogma beschreibt eine unumstößliche Wahrheit. Francis Crick bereute später, diesen unwissenschaftlichen Begriff verwendet zu haben.
Unterschied DNA und RNA – Funktion
Wenn Abschnitte der DNA abgelesen und in eine RNA-Sequenz übertragen werden, so nennt man diesen Vorgang Transkription. “Kodierende Abschnitte” sind solche, die zur Bildung eines Polypeptides beitragen.
Kodierende Ribonukleinsäuren
Als kodierende Ribonukleinsäuren bezeichnet man die mRNAs (messenger-RNAs), die im Zuge der Transkription gebildet werden.
Diese werden, zumindest bei Eukaryoten, noch weiterer verändert, weswegen man die RNA, die nach der Transkription bei Eukaryoten entsteht, zunächst als prä-mRNA bezeichnet. Der Prefix “prä” symbolisiert eine Vorstufe der mRNA, da diese noch um einige Bestandteile ergänzt wird oder anderweitig abgeändert werden kann.
So wird bspw. bei Eukaryoten an die prä-mRNA ein sogenannter Poly(A)-Schwanz an das 3'-Ende angehängt. Es handelt sich um eine Vielzahl von Adenosin-Nukleotiden, die unter anderem zur Regulierung der Translation verwendet werden.
Allerdings kann RNA viele weitere Aufgaben neben der besagten Bildung von einem Polypeptid einnehmen:
Nichtkodierende Ribonukleinsäuren
Andere RNA-Sequenzen, die anhand von DNA-Abschnitten transkribiert worden sind, werden nicht zur Bildung von Polypeptiden herangezogen. Sie können stattdessen auf viele unterschiedliche Arten die Genexpression beeinflussen.
Nichtkodierende Ribonukleinsäuren (engl. non-coding RNA, häufig auch im dt. als Abkürzung ncRNA) ist ein Sammelbegriff für sämtliche Ribonukleinsäuren, die nicht wie die mRNA zu Polypeptiden übersetzt werden.
Genexpression beschreibt, wie die Information eines Gens in der DNA in einem Organismus “exprimiert”, also ausgedrückt wird.
Da eine Vielzahl von ncRNAs mit diversen Funktionen existiert, werden im Folgenden lediglich die bedeutsamsten vorgestellt:
Ribozyme
Die Bezeichnung Ribozyme ist eine Wortkomposition aus “Ribonukleinsäuren” und “Enzymen”. Dabei ist diese Wortzusammensetzung sehr treffend, denn Ribozyme sind nichts anderes als Ribonukleinsäuren, die als Enzyme arbeiten. Sie katalysieren damit Reaktionen innerhalb von Zellen und können ohne Zwischenstufe (wie es bei Polypeptiden der Fall wäre) direkt anhand der DNA transkribiert werden.
Ribosomale-RNA (rRNA)
Ribosomale-RNA (rRNA) wird ein Bestandteil der Ribosomen genannt. Die Ribosomen, an denen die Translation stattfindet, setzen sich aus rRNA und Proteinen zusammen.
Die rRNA hat eine enzymatische Funktion, weswegen sie ein Ribozym ist (vgl. oben). Sie kann bis zu 90 % des gesamten Inhalts einer Zelle von Ribonukleinsäuren darstellen.
Transfer-RNA (tRNA)
Die Transfer-RNA (kurz tRNA) ist ein wesentlicher Bestandteil bei der Protein-Biosynthese. Sie besitzen ein sogenanntes Anti-Codon, das komplementär zu einer spezifischen Abfolge auf der mRNA ist. Die tRNA kann dadurch die passende Aminosäure im Ribosomkomplex bei der Translation übertragen.
Ein Codon ist ein Sequenzabschnitt auf der mRNA, der aus drei Nukleotiden besteht.
Das Anti-Codon der tRNA ist komplementär zum Codon auf der mRNA.
Wenn Du mehr über die Informationsübertragung herausfinden möchtest, dann lese gerne den Artikel “Translation”.
Mehr über die möglichen Codons ist im Artikel “Codesonne” zu finden.
Sonstige Nichtkodierende Ribonukleinsäuren
Es gibt noch viele weitere Ribonukleinsäuren, die nicht kodierend sind und wichtige Aufgaben in der Genexpression besitzen und vermutlich sogar noch weitere, die noch gar nicht bekannt sind. Eine kurze Auflistung der Namen findest Du im Folgenden:
- asRNA, antisense-RNA
- circRNA, zirkuläre RNA
- hnRNA, heterogene Kern-RNA
- miRNAs, microRNAs
- Riboswitches
- saRNA, selbstamplifizierende RNA
- siRNA, small interfering RNA
- shRNA, small hairpin RNA
- snoRNA, small nucleolar-RNA
- snRNA, small nuclear-RNA
- lncRNA, long non-coding RNA
- piRNA, Piwi-interacting RNA
- tracrRNA, transactivating crRNA
Dies zeigt eindrucksvoll, wie viele RNA-Formen es gibt und welche Fülle an Forschungsmöglichkeiten in diesem Teilbereich der Genetik besteht.
DNA und RNA Primer
Die Bezeichnung Primer ist Dir vielleicht bereits im Kontext der DNA-Replikation oder der Polymerase-Kettenreaktion begegnet. Aber was ist damit gemeint?
Primer sind kurze Abschnitte aus meist 15 bis 30 Nukleotiden. Sie werden als Startpunkt zur DNA-Replikation verwendet.
Die Primer bieten an ihrem 3'-Ende einen passenden Einstiegspunkt für Polymerasen. Die Primer können sowohl aus DNA und RNA bestehen. Eukaryoten und Prokaryoten benutzen allerdings in den überwiegenden Fällen Primer aus RNA.
Primer aus DNA werden in der Polymerase-Kettenreaktion (PCR) verwendet. Wenn Du mehr über die PCR erfahren möchtest, schau’ bei dem Artikel “Polymerase Kettenreaktion” vorbei.
Gemeinsamkeiten & Unterschiede DNA und RNA – Polymerase
Polymerasen sind ein wesentlicher Bestandteil von Lebewesen, da diese den Aufbau von Nukleinsäure-Polymeren ermöglichen.
Gemeinsamkeiten DNA und RNA – Polymerase
Eine Polymerase ist ein Enzym, das üblicherweise aus mehreren Proteinen besteht. Es katalysiert den Aufbau von Polymeren, bspw. von Nukleinsäuren, aus kleineren Bestandteilen, aus Monomeren.
Im Kontext von Nukleinsäuren bauen Polymerasen die Nukleinsäure-Polymere aus ihren Monomeren, den Nukleotiden, auf.
Die einzelnen Polymerasen unterscheiden sich allerdings strukturell, je nachdem, ob sie entweder zum Aufbau der DNA verwendet werden (bei der Replikation) oder bei der Transkription von DNA zu RNA oder RNA zu RNA.
Unterschiede DNA und RNA – Polymerase
Die Unterschiede sind hauptsächlich darauf zurückzuführen, ob die Polymerasen nun den Aufbau eines DNA- oder RNA-Strangs katalysieren.
Polymerasen der DNA
DNA-Polymerasen spielen bei der DNA-Replikation eine wichtige Rolle. Sie fügen komplementäre Nukleotide anhand eines zu kopierenden Stranges, dem Matrizenstrang, an. Hierbei laufen sie die DNA in 5' → 3' Richtung ab.
Daneben besitzen sie eine “proof reading”-Funktion: Nukleotide, die falsch eingesetzt worden sind, werden entfernt und ersetzt.
DNA-Polymerasen setzen regelmäßig zunächst falsche Nukleotide ein. Diese werden allerdings erkannt und anschließend herausgeschnitten. Dennoch hat die DNA-Replikation durchschnittlich einen Fehler nach 109-1010 Nukleotiden.
Genaueres zur DNA-Replikation findest Du im gleichnamigen Artikel “DNA-Replikation”.
Polymerasen der RNA
RNA-Polymerasen werden zum Aufbau von Ribonukleinsäuren verwendet. Hierbei muss allerdings zwischen DNA- und RNA-abhängigen Polymerasen unterschieden werden.
- RNA-abhänginge RNA-Polymerasen (engl. RNA-dependent RNA polymerase, kurz RdRp) bilden Ribonukleinsäuren anhand einer anderen RNA. Sie führen also eine RNA-Replikation durch.
- DNA-abängige RNA-Polymerasen (DNA-dependent RNA polymerase, kurz DdRp) bilden anhand von DNA eine Ribonukleinsäure. Sie sind die häufigste Form von Nukleinsäure-Polymerasen.
Wie auch DNA-Polymerasen besitzen RNA-Polymerasen üblicherweise eingebaute Mechanismen, die Fehler umgehen (“proof-reading”) und Endsequenzen erkennen.
In Prokaryoten kommt nur eine Form von RNA-Polymerasen vor, in Eukaryoten allerdings eine Vielzahl, die anhand einer römischen Ziffer identifiziert wird, bspw. RNA-Polymerase I oder RNA-Polymerase IV.
Gemeinsamkeiten & Unterschiede DNA und RNA – Viren
Viren befinden sich an der Grenze zu unserer Definition von Leben. Sie erfüllen nicht alle Voraussetzungen eines Lebewesens, bspw. bestehen sie nicht aus Zellen oder können ihre physiologischen Funktionen aufrechterhalten. Sie benötigen einen geeigneten Wirt, der ihren Mangel an Funktionalität ausgleicht.
Gemeinsamkeiten DNA und RNA – Viren
Gemeinsam haben DNA und RNA Viren ihren strukturellen Aufbau. Ein Virion, das ein Virus-Partikel außerhalb der Wirtszelle ist, besitzt folgende Bestandteile:
- das virale Genom (Erbgut),
- eine Proteinhülle (Kapsid) und
- manchmal noch eine Virushülle.
 Abbildung 13: SARS-CoV-2 mit einer Lipidhülle und Membranproteinen
Abbildung 13: SARS-CoV-2 mit einer Lipidhülle und Membranproteinen
Unterschied DNA und RNA – Viren
Die Unterschiede zwischen DNA- und RNA-Viren liegen, wie die Namen nahelegen, in ihrem Genom.
Das Genom kann doppel- oder einzelsträngig, in Segmenten oder unsegmentiert, zirkular oder linear sein.
DNA-Viren: Genom und Polymerasen
Das Genom der DNA-Viren setzt sich aus DNA zusammen. DNA-Viren kommen seltener als RNA-Viren vor und sind weniger anfällig für Mutationen. Dies ist auf die höhere Stabilität von DNA und auf die Korrekturmechanismen der DNA-Polymerasen zurückzuführen.
Hepatitis-B-Virus
Das Hepatitis-B-Virus ist ein DNA-Virus, der sich im Menschen nahezu ausschließlich in Leberzellen vermehrt. Das Virus verursacht die Erkrankung von Hepatitis B. Diese Krankheit kann sich, in chronischen Fällen, zu einer Leberzirrhose entwickeln.
RNA-Viren: Genom und Polymerasen
Das Genom der RNA-Viren setzt sich aus RNA zusammen. RNA-Viren sind die häufigsten Formen von Viren und sind anfälliger zu Mutationen als DNA-Viren. Dies führt zwar häufiger zu Fehlmutationen und damit zu einem Fitness-Verlust dieser Viren, gleichermaßen ermöglicht es ihnen allerdings auch schneller an neue Organismen angepasst zu werden und eine “Immunflucht” zu vollziehen.
Dies ist auf eine geringere Stabilität der RNA und das häufige Fehlen von “proof-reading” Funktionen der RNA-Polymerasen in den RNA-Viren zurückzuführen.
Human immunodeficiency virus (HIV)
Das HI-Virus ist ein RNA-Virus. Sofern die Infektion nicht behandelt wird, führt diese nach einer in der Regel symptomfreien Latenzzeit zu AIDS (acquired immunodeficiency syndrome).
Eine Infektion mit dem HI-Virus kann mittels Medikamenten unterdrückt werden. Hierbei wird die Reproduktion des Virus im Körper derartig stark verhindert, dass die Erkrankung AIDS lange herausgezögert werden kann und behandelte Personen nicht mehr infektiös sind, da die Konzentration von Virus-Partikeln im Blut zu gering ist.
Dennoch ist ein Träger des Virus auf Lebenszeit damit behaftet und kann nicht geheilt werden.
Ein Grund, warum bisher keine Impfung gegen das HI-Virus entwickelt werden konnte, ist, dass das Virus häufig mutiert und damit dem Immunsystem entkommt (“Immunflucht”); ein typisches Merkmal von RNA-Viren.
Unterschied DNA RNA Tabelle
| Aspekt | DNA | RNA |
| Pentose | Desoxyribose | Ribose |
| organische Basen | Adenin (A), Guanin (G), Cytosin (C), Thymin (T) | Adenin (A), Guanin (G), Cytosin (C), Uracil (U) |
| Aufbau | Doppelsträngig | Meist einzelsträngig, es können aber auch Paarungen von Nukleotiden im Einzelstrang auftreten |
| Länge | äußerst lang (häufig Millionen von Nukleotiden) | eher kurz (Dutzende bis Tausende von Nukleotiden) |
| Funktion | dauerhafte, sichere Informationsspeicherung | Informationsspeicherung, -übertragung, Regulierung, Katalyse |
| Polymerasen | DNA-Polymerasen zum Aufbau von DNA-Polymeren aus DNA-Nukleotiden | RNA-Polymerasen zum Aufbau von RNA-Polymeren;- RNA-abhängige RNA-Polymerasen (RNA-dependent RNA polymerase, RdRp)
- DNA-abhänginge RNA-Polymerasen (DNA-dependent RNA polymerase, DdRp)
|
| Viren | DNA-Viren enthalten DNA im Genom | RNA-Viren enthalten RNA im Genom |
Unterschied DNA RNA - Das Wichtigste
- DNA und RNA unterscheiden sich im Aufbau:
- Pentose:
- DNA verwendet Desoxyribose.
- RNA verwendet Ribose.
- Organische Basen:
- DNA verwendet Adenin (A), Guanin (G), Cytosin (C) und Thymin (T).
- RNA verwendet dieselben Basen, allerdings anstelle von Thymin (T) Uracil (U).
- Doppelsträngigkeit:
- DNA kommt doppelsträngig vor.
- RNA kommt üblicherweise einzelsträngig vor. Es können Paarbindungen im einzelsträngigen Molekül auftreten, bspw. bei der tRNA.
- Länge der Polymere:
- DNA ist äußerst lang (können Millionen von Nukleotiden sein).
- RNA ist vergleichsweise kurz (Dutzende bis Tausende von Nukleotide).
- DNA und RNA unterscheiden sich in Funktion:
- DNA speichert langfristig Information.
- RNA dient zur kurzfristigen Informationsspeicherung, -übertragung und Regulierung der Genexpression.
Nachweise
- David Sadava, et al. (2019). Purves Biologie. Springer.
- Jeremy M. Berg, et al. (2018). Stryer Biochemie. Springer.
- Jochen Graw (2015). Genetik. Springer.
- Abb. 3: Nucleotide, Nukleoside general (https://commons.wikimedia.org/wiki/File:Nucleotide_nucleoside_general.svg) von Yikrazuul (https://commons.wikimedia.org/wiki/User:Yikrazuul) unter der Lizenz CC BY-SA 3.0 (https://creativecommons.org/licenses/by-sa/3.0/deed.en)
- Abb. 10: Speckle-bellied lungfish (Protopterus aethiopicus) (https://www.flickr.com/photos/40295335@N00/4840412198) von Joel Abroad (https://www.flickr.com/photos/40295335@N00/) unter der Lizenz CC BY 2.0 (https://creativecommons.org/licenses/by/2.0/?ref=openverse.)
- Abb. 13: Sars-CoV-2 (https://commons.wikimedia.org/wiki/File:Coronavirus._SARS-CoV-2.png) von Alexey Solodovnikov (https://commons.wikimedia.org/wiki/User:AlexeySolodovnikov) und Valeria Arkhipova unter der Lizenz CC0 1.0 (https://www.rcsb.org/pages/policies)
Ähnliche Themen in Biologie
Verwandte Themen zu Genetik





